
Review on Open-Vocabulary
Open-Vocabulary相关文章的调研和模型回顾。
概述
Open Vocabulary
利用已有的预训练模型,如语言大模型(LLM)和视觉语言模型(VLM)中学习的先验知识,在闭集模型上实现open能力。无需重复在大规模数据集上重复训练不同模型,节约成本。
任务
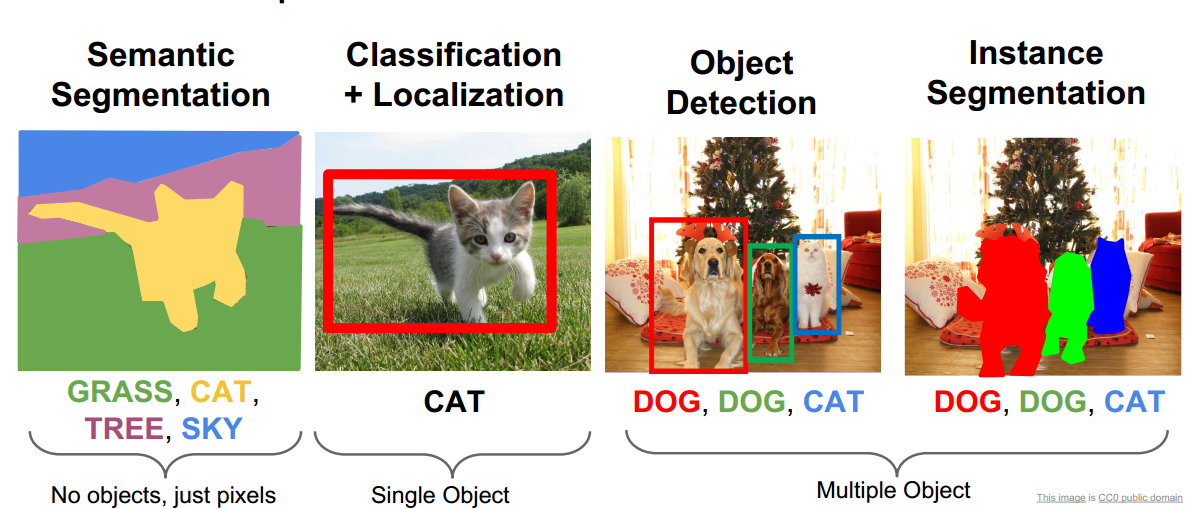
- object detection
检测画面中目标,bunny-box - segmentation
semantic: 关注像素属于何个类别
instance: 关注像素属于何个实例 - video understanding
主要是视频的物体跟踪、物体分割 - 3D scene understanding
主要是3D检测/分割和场景理解,3D+text等跨模态任务
学习方式
- Close-set learning
训练集和测试集共享同样的类别/Label space;
不可处理新的类别 - Open-set learning
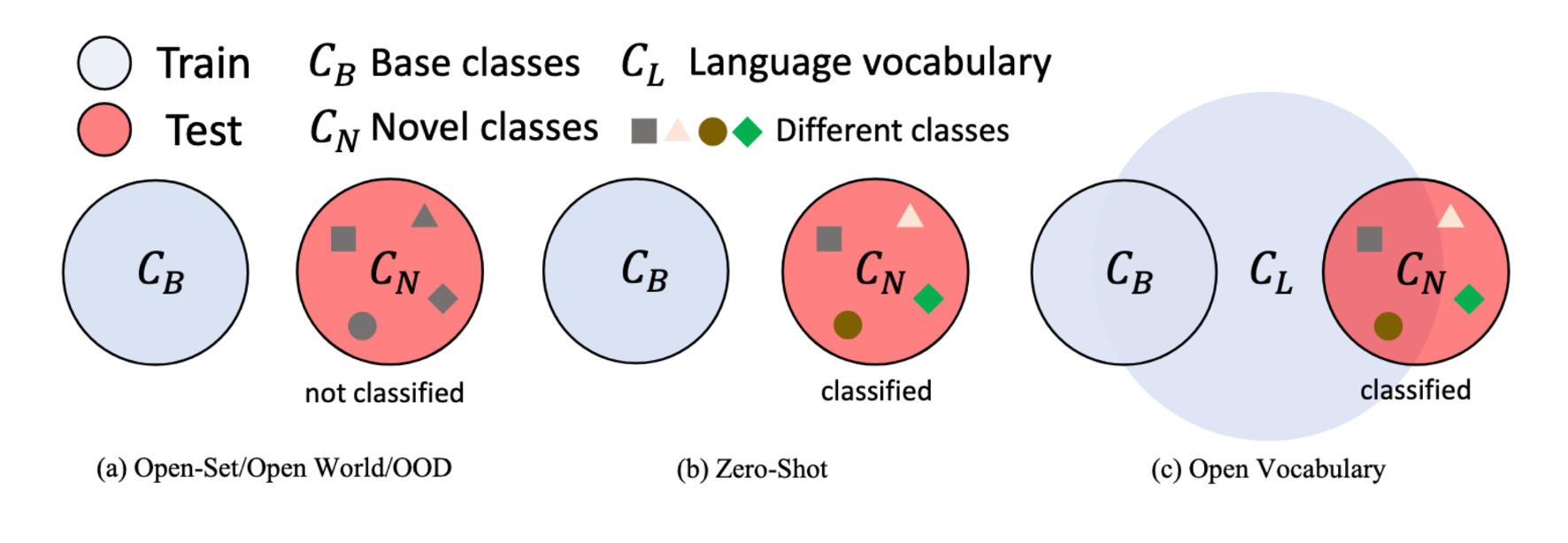
测试集上存在新的类别,将其拒绝为未知一类。 - Zero-shot learning
测试集上存在新的类别,模型预测并分类新的类别。训练时未知类别严格不可获得。
局限:训练时缺少未知类别的样本,易被当作背景;因此推理时过多依赖词嵌入,未知类的视觉信息利用不充分。 - Few-shot learning
用少量样本提升识别性能。 - Open-vocabulary learning
训练时可用大规模的语言词汇(类别)知识,可用预训练VLM区分未知类。(与ZSL相比)可以利用视觉相关的语言数据进行辅助监督。
优势:语言数据的标注成本更低,image caption容易获得;语言数据的类别规模更大,利于泛化
识别和分割
Few-shot
Few-Shot Semantic Segmentation:对查询图像进行像素层面的分割;
Few-Shot Instance Segmentation:用少量样本识别和分割对象。分为单分支和多分支方法。
Zero-shot
判别方法和生成式方法。
- SPNet: 将像素映射到语义词嵌入空间,将像素特征投影到类别的概率。
- ZS3Net: 生成式模型,根据词嵌入生成未知类别的像素特征。
上述方法鲁棒性差,因为词嵌入更多针对物体对象而非像素
- PADing:提出了三种segment的统一框架
预训练大模型
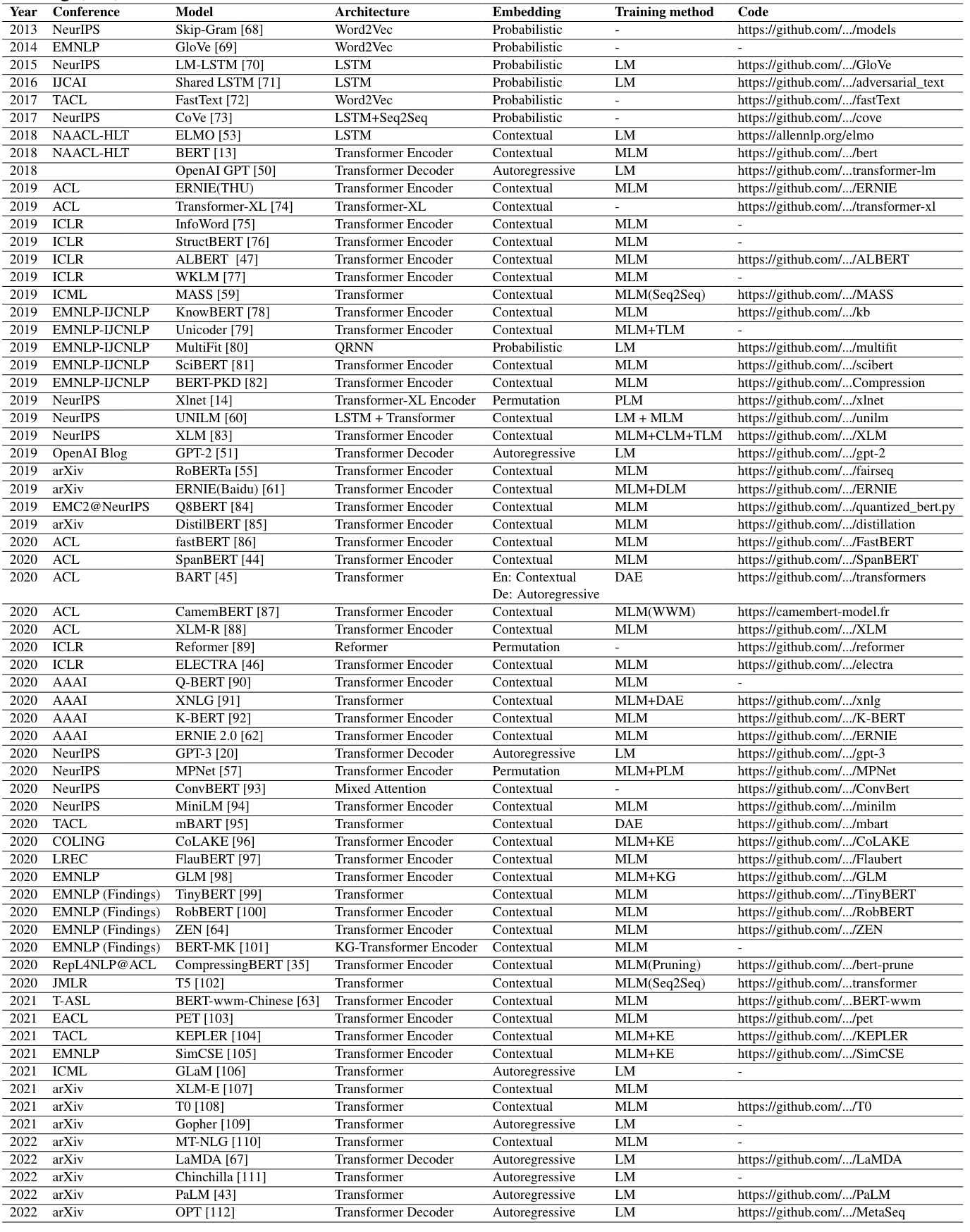
NLP
任务
- Language Modeling (LM):
- Mask Language Modeling (MLM): 随机用MASK掩盖单词,在预训练时学习预测MASK
例如BERT使用MLM预训练。 - Denoising AutoEncoder (DAE): 在原始语料中加入噪声,学习进行重组
BART采用自编码器。 - Next Sentence Prediction (NSP): 训练模型理解语句之间的关系。输入两个不同句子,学习正确预测顺序
BERT使用NSP预训练。 - Sentence Order Prediction (SOP): 和NSP相比使用交换顺序的句子作为负例
例如ALBERT使用该任务预训练。
模型/结构
- BERT
Transformer encoder结构,双向编码器。预测masked单词和句子是否上下文。词嵌入为上下文
缺点:文本双向编码,但缺少的token独立预测,因此泛化性能不强;预训练任务和生成任务不同 - GPT
Transformer decoder结构,自回归解码器提取特征。zero/few-shot prompt建模
训练时根据前文预测下一个单词,微调以用于下游任务。词嵌入为概率
缺点:仅用上文预测下文,不能学习双向信息 - BART
encoder-decoder结构,去噪自编码器的seq2seq模型。
用加噪再重建的方式预训练。词嵌入:上下文编码器,自回归解码器
加噪声方式:mask单个词/删除词/mask扩展长度/句子重排/文档重排
其他预训练模型
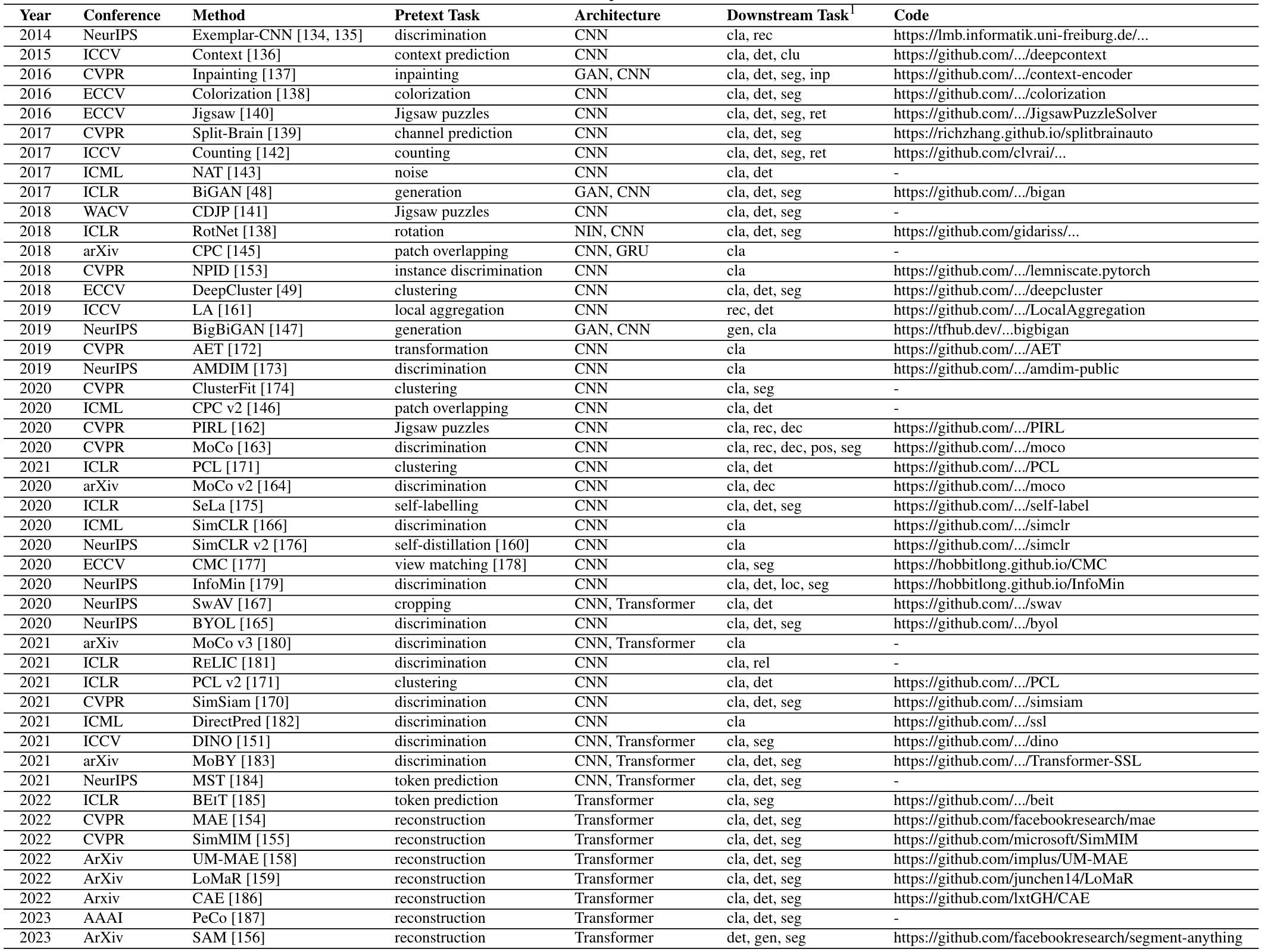
CV
CLIP
- 核心思路:通过在大规模图像-文本数据集上进行对比学习,使模型将语义相关的图像特征和文本特征映射到同一个多模态的特征空间。
- 结构
图像encoder:使用传统的卷积神经网络ResNet和Vision Transformer(ViT)提取图像特征
文本encoder:Transformer结构 - 过程
把图像文本对分别输入图像和文本的编码器,产生图像特征和文本特征;将特征用内积/余弦相似度计算匹配程度;用匹配的作为正例、不匹配作为负例,越匹配loss越小,计算损失;
CLIP实现图像特征和文本特征的对齐,得到通用的语义表示。从图像-文本对中学习的知识可以用于下游任务,open vocabulary学习,zero-shot任务和其他3D任务。
CV中的预训练模型汇总
方法和模型
前置知识
基于像素的检测/分割
分为语义层面的、实例层面的。
- Semantic segmentation:
一般基于FCN及其改进方法;用Transformer结构代替了CNN预测头 - Instance detection:
两阶段方法:由RPN对前景对象打分,高分的对象再由检测头细化。能更好识别前景,多用于open vocabulary物体检测中
一阶段方法:逐像素方法输出识别框和标签;加上焦点损失/特征金字塔网络,效果有时更好 - Instance segmentation: 比检测更进一步,关注如何表示实例的mask。
从上到下:基于detector再加上额外的mask head;表现取决于detector
从下往上:根据实例的semantic segmentation进行实例聚类,产生mask;表现取决于分隔结果和聚类方式
基于查询的检测/分割
基于Transformer的方法更简洁和统一。
- Detection Transformer: CNN为主干,加上Transformer的encoder和decoder,用对象查询代替了anchor
object query: 训练时建立一个一一映射,基于预测的映射和GT的误差(由label/box/mask的误差构成):
- 对于detection: 分类误差和box回归误差
- 对于instance-wised segmentation: 分类误差和分割误差
不可直接检测新的类别,但是常用于open-vocabulary中基本的检测器和分割器
大规模VLP
- two-stream neural networks:基于视觉Transformer模型,分别处理视觉和语言信息,并由另一个Transformer结构(交叉注意力)融合
- CLIP/Align:在图像-文本对上的大规模预训练,表明匹配图像和caption已经可以产生强泛化的模型
Open vocabulary在相关任务中利用VLP蕴含的视觉-文本知识。
Open Vocabulary Object Detection
知识蒸馏
利用VLM,将其知识(新的类别)蒸馏给闭集detector。
- ViLD:有text和image两个分支。
text:文本嵌入由VLM的文本编码器获得
image:先由一个detector获得区域嵌入,再将裁剪的图像送入VLM的视觉编码器得到图像嵌入 - HierKD:利用单阶段detector,提出全局的语言-视觉知识蒸馏模块
上述两种都使用基于像素的检测器。可以换用基于查询的检测器,需引入detector 区域表示和CLIP区域表示的嵌入匹配误差IMP。
- OADP:认为只能蒸馏物体层面的知识给下游detector,提出了全局/区块蒸馏的方式。
利用更细粒度的信息(属性/描述/关系):
- PCL:使用一个Caption模型给实例生成更详细的描述
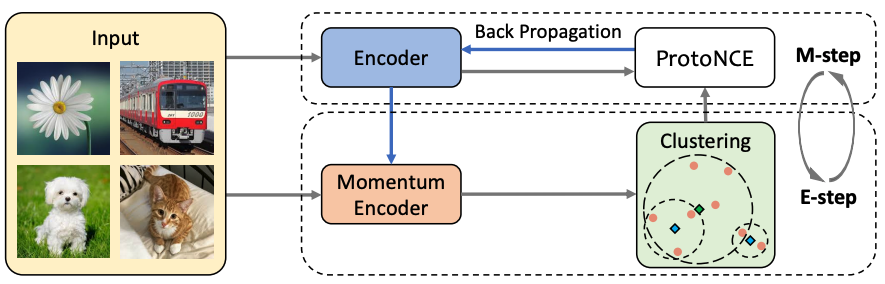
- OVRNet:在开放词汇场景中同时检测物体和视觉属性
区域文本预训练
区域文本对齐,将视觉特征的新类别和文本特征映射到一个对齐特征空间。
- OVR-CNN:使用caption数据进行open vocabulary的新类别检测
过程:训练一个ResNet;用图像-文本对训练一个V2L层,将特征从视觉空间映射到语义空间,不受标签闭集的限制。
把可学习的分类器替换为预训练模型的text encoder;RoI得到区域视觉特征送入V2L层映射到语义空间; - Attribute-Sensitive OVR-CNN:对齐视觉区域和BERT输出的上下文单词嵌入
使用一种采样策略,增强模型对caption中形容词/动词短语/位置短语的敏感 - RegionCLIP:通过匹配图像区域和区域层面的描述,学习区域特征表示
过程:用CLIP给区域-文本对产生pseudo标签,用对比误差进行匹配后,再用人类标注数据集微调视觉编码器
Prompting建模
使基础模型适应不同领域的方法。将学习到的提示融入基础模型中,模型能将其知识迁移到下游任务中。
prompts输入VLM的编码器得到类别名称的嵌入,但负例不属于任何类别。
- PromptDet:在prompt中引入类别的描述,以及考虑类比名称出现的位置。
- DETR:提示基于CLIP的区域分类器的区域特征,缩小整幅图像和区域分布之间的差距
- CORA:通过对类别敏感匹配机制,学习可泛化的localization
其他模型汇总
Open Vocabulary Segmentation
视觉-文本大模型用于语义分割,以提高识别和分割性能;可看做一种稠密的分类任务。常用CLIP作为VLM。
- LSeg:
对齐了类别标签的文本嵌入和输入图像的嵌入,因此利用VLM的泛化性能分割没有定义的物体,实现open - Fusioner:
用self-attention算子,通过基于Transformer的框架融合视觉和语言 - ZegFormer
将分割任务视为:不考虑类别的分割+得到mask的分类
使用VLM中的label嵌入对分类mask,使用CLIP - Vision编码器来得到语言对齐的视觉特征。 - MaskCLIP
在预训练CLIP中加入一个mask attention模块,利用CLIP的特征更有效 - TagCLIP
提出了一个可信token模块,在像素分类前先提前预测包含物体的像素,避免错误识别的像素被分到新类别
也可利用扩散模型的文本-图像的泛化能力进行open的分割,如ODISE、OVDiff。OVDiff进行mask分类时用训练好的Diffusion生成各种类别的基本图像,并进行最优匹配以确定类别。
其他模型汇总
Open Vocabulary Video Understanding
VLM的视觉知识用于物体追踪和实例分隔,基于closed追踪器构建open追踪器。
- OVTrack
引入大型VLM处理open vocabulary的多目标追踪。利用RPN打分得到RoI区域,再通过CLIP进行知识蒸馏。采用单独的追踪头
视频实例分割任务:
- MindVLT
采用固定的CLIP主干。提出使用open vocabulary分类器来分割和跟踪未知类别,从而泛化到新类别。 - OpenVIS
和上面的方式不同。为实例生成与类别无关mask,利用这个mask裁剪原始图像,输入CLIP-vision的编码器计算类别分数。
Open Vocabulary 3D Understanding
3D识别
VLM可通过图像-文本对训练,在2D上zero-shot/few-shot学习。但3D上的点-文本对不好获得。
- PointCLIP
本质是把3D点云转换为CLIP可识别的图像,从而利用CLIP的知识识别open的类别。
过程:三维点云投影到二维平面,CLIP视觉编码器从投影的深度图中提取视觉特征,从对齐而点云特征和语言编码器提取的语言特征
缺点:直接投影为2D深度图会导致较差的性能
改进的模型:
- CLIP2Point
通过对比学习,对齐了CLIP图像编码器得到的RGB图像特征和一个深度信息编码器得到的深度特征。
采集图像-深度对用来训练上面两个编码器,推理时只利用深度encoder。于是再通过CLIP本身对齐的图像特征和文本特征,深度特征就和文本特征对齐了。 - PointCLIP v2
提出了一种更真实的3D点云到2D的形状投影,以及基于LLM的3D prompt生成方案,在没有额外注释下性能显著提高。
投影会损失信息,无法完整利用3D点云的信息。一些新的方法:
- ULIP
收集多模态三元组(点云、图像和文本)来训练3D主干。
CLIP对齐了语言和图像编码器,因此ULIP只需将3D主干对齐到图像-语言特征空间。
优点:统一点云、图像和文本三种模态,可用于更多下游任务,比如文本检索3D物体(text2point);对齐3D和2D带来了原生的3D上的open vocabulary能力
缺点:需要在收集得多模态三元组上训练,规模太小 - OpenShape
扩展了数据集和结构主干。提出了一个文本-3D形状的87万规模的数据集,超过一千个类别;使用了更大的3D主干
提高了3D zero-shot能力
3D物体检测
3D物体检测的训练集难以获取,因此大多数closed-set检测器难以泛化到新的类别上。
- OV-3DETIC和OV3DET
将检测任务解耦为定位和识别任务。于是定位任务可以采用预训练的2D检测器,反向投影形成3D的包围盒实现定位。识别任务则将3D和2D编码器的区域特征和对应的文本特征对齐。这一步使得推理时可以用CLIP中的知识泛化到新的类别上。
3D场景理解
同样面临缺少从同一个场景中获取点云-文本对数据的问题。
- PLA
从多视角图片中提取特征,再用语言大模型生成描述来获得语言特征,进行对齐。 - OpenScene
思路是将每个点的三维特征与每个像素的CLIP特征联系起来。将2D像素反向投影到3D空间,把点云中的每个点与不同视图中的几个像素的特征进行集成。 - PartSLIP和SATR:直接把3D点云和网格投影到2D平面,利用GLIP进行定位和分割。
- OpenMask3D:主要是3D分割任务,利用了多个大模型
选择视图然后把3D mask投影为2D图像。2D mask通过SAM进一步细化。最后联合CLIP语言编码器,把2D mask输入到CLIP视觉编码器中生成标签预测。
参考文献:
[1] Wu, J., Li, X., Yuan, H., Ding, H., Yang, Y., Li, X., Zhang, J., Tong, Y., Jiang, X., Ghanem, B., & Tao, D. (2023). Towards Open Vocabulary Learning: A Survey. ArXiv, abs/2306.15880.
Review on Open-Vocabulary